
몇 달 전 구글이 만든 인공지능(AI) 서비스 ‘제미나이’가 서비스를 중단한 일 기억하나요? 제미나이가 역사를 왜곡하거나 인종 편향적인 이미지를 만든다는 논란에 휩싸여 서비스 시작 20일 만에 중단한 건데요. 잊을만하면 생기는 AI 오류, 왜 일어나고 어떤 대처 방안이 있는지 함께 살펴보겠습니다
무슨 일이더라?
제미나이가 실제 사실과 전혀 다른 이미지를 생성하며 논란이 일었습니다. 예를 들면 제미나이에 제2차 세계 대전 당시 독일 군인의 모습을 그려달라고 하자, 아시아 여성과 유색인종 남성의 이미지를 그린 것. 또 아인슈타인을 그려달라고 했더니 유색인종 이미지를 내놓았습니다. AI가 잘못된 정보를 내놓은 게 처음은 아닌데요. 챗GPT도 세상에 없는 논문을 가짜로 만들어 알려주는 등 사실이 아닌 정보를 지어내서 답한 사례가 많았습니다.


AI는 왜 틀린 답을 하는 거야?
챗GPT나 제미나이 같은 요즘 인공지능은 거대언어모델(LLM)이라는 기술을 사용합니다. LLM은 AI가 엄청나게 많은 텍스트를 스스로 학습해, 언어들 사이의 관계나 맥락을 찾아내는 기술인데요. 여기에는 두 가지 문제가 있습니다.

😵 틀린 정보로 배웠어
AI가 학습한 데이터 중에 틀린 정보가 있을 수 있습니다. 사람들의 일반적인 편견과 혐오가 반영된 데이터도 많은데요. 예를 들어 AI에 다양한 얼굴을 보여주고 이중 범죄자를 고르라고 하니 유색인종만 고르는 일도 있었습니다. 그렇다고 이런 편향을 교정하는 것도 쉽지 않은데요. AI에 다양성을 학습시키자, 유색인종이나 아시아 여성을 과도하게 묘사해 왜곡된 결과물을 내놓는 일이 생기는 것(=과잉 보정).
🤔 몰라도 아는 척하게 배웠어
애초에 AI가 그럴싸한 답변을 하도록 만들어졌다는 분석도 있습니다. AI는 답을 몰라도 모른다고 하지 않고, 자기가 학습한 데이터를 확률적으로 조합해 ‘그럴듯한’ 답변을 내놓거든요(=환각 현상).
전문가들은 아직은 AI의 이런 ‘거짓말’이 인간이 알아챌 수 있는 수준이지만, 앞으로 AI의 수준이 높아지면 가짜정보를 구별하기 어려워져 큰 문제가 생길 수 있다고 경고합니다.
그럼 어떤 대책이 있을까?
기업들의 노력을 살펴보면:
📶 기술로 검증하고
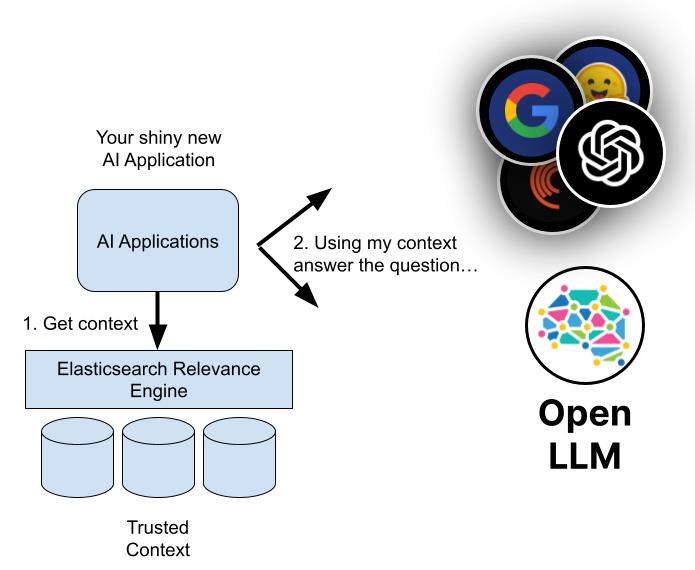
AI가 가진 데이터를 다른 데이터와 비교해 답변을 검증하게 하는 기술(=검색 증강 생성·RAG)을 개발하는 게 요즘 트렌드입니다. AI가 자기가 학습해 만든 답변을 내놓기 전에 정확한 데이터와 한 번 더 비교해 교차검증을 하게 만드는 원리인데요. 기업이나 공공기관, 개인이 제공한 최신 데이터를 바탕으로 해서 정확도가 높습니다.
🔬 사람이 검증하고
사람이 직접 AI의 가짜 정보를 잡아내기도 합니다. 최근 구글, 오픈AI, 네이버, 카카오 등 빅테크 기업들은 소프트웨어 보안을 담당하던 ‘레드팀’을 업그레이드해 ‘AI 레드팀’을 만들고 있다고. AI에 일부러 틀린 답을 유도해 그걸 수정하는 겁니다

🤝 함께 방안 찾고
여러 기업이 모여 함께 AI 가이드라인을 만들기도 합니다. 작년에는 구글·마이크로소프트·오픈AI 등이 모여 AI 안전성을 논의하는 기구를 만들었습니다. 다만 아직은 AI 윤리 문제가 기업의 자율로만 맡겨져 있다 보니 이걸 아예 법으로 규제해야 한다는 목소리도 나옵니다.
'NEWSLETTER > 산업 LETTER' 카테고리의 다른 글
| 반도체 점유율 6%까지 떨어진 일본의 새로운 반도체 전략 (0) | 2024.04.28 |
|---|---|
| 테슬라, 역시나 부진한 실적 1분기 매출 급감 (2) | 2024.04.26 |
| 한계 다다른 OTT 업계, 스포츠가 답이다 (1) | 2024.04.26 |
| SK하이닉스 24년 1분기 어닝 서프라이즈 (0) | 2024.04.26 |
| 점점 더 거세지는 햄버거 전쟁 (0) | 2024.04.24 |



